Application of Data Mining Method in Credit Card Approval Process
Application of Data Mining Method in Credit Card Approval Process
Research Paper
Dunyu Yang
Abstract
The credit card application process is a critical process for banking institutions to manage risk and ensure its financial stability. This research aims to develop a predictive model for classifying credit card applicants using data mining techniques. By leveraging historical credit payments and personal information of applicants, we aim to optimize the credit card approval process, enhance accuracy, and reduce labor costs of banking institutions. The model utilizes the Random Forest classification algorithm, to identify key features influencing creditworthiness and improve the decisionmaking process in credit card issuance.
I. Introduction
Credit cards are widely used in a lot of different situations these days. Whether shopping online or offline, credit cards are favored because of the convenience they offer. In addition to everyday spending, credit cards also play a key role in travel and emergencies. Besides, many credit cards offer additional benefits such as cash rebates, airline miles, points rewards, etc., attracting more people to use credit cards. According to relevant statistics, there were 441 million open credit card accounts in the U.S. as Q3 2022, and seventy-seven percent of U.S. adults have at least one credit card. [1] It is safe to say that credit cards have become an integral part of modern life.
While credit card brings convenience to society, it also carries risks. For example, if cardholders do not have a clear financial plan or are unable to control their spending, credit cards could get them into deep trouble. Once cardholders are unable to pay their debts on time, they may face higher interest rates and late fees, which becomes a vicious cycle that will make their debts higher and might eventually lead to personal bankruptcy. With more people going bankrupt, public security may deteriorate.
However, we cannot simply blame credit card users for the negative effects of using credit cards. As credit card issuing organizations, banks have an obligation to curb credit card abuse by setting card issuance criteria in order to stop the bad things before they start. One possible solution is to conduct credit assessments of credit card applicants, evaluating their credit history, income status, employment, education, etc., to determine whether or not to issue a credit card to them. With a proper credit scoring strategy, economic stability can be enhanced, trust between financial institutions and their customers can be strengthened, and responsible lending habits can be promoted overall.
The history of credit dates back thousands of years, but the modern version of the credit card is less than 100 years old. [2] As financial markets became more complex and globalized, a more systematic and reliable approach to managing credit card risk was needed. With advances in computer technology and the application of big data over the past few decades, new models began to emerge.
The main objective of this study is to explore the application of big data and data mining in the credit card application approval process and to optimize machine learning models to address the unique challenges brought to the financial system by the data age. This will improve the speed and reliability of credit card approval and reduce labor costs and the subjective influence of human judgment on the approval process.
In addition to pursuing high accuracy and speed, the interpretability of the model is also crucial in practical applications. Financial institutions such as banks need to understand not only which applicants might overdue but also how the model makes these judgments. This understanding can support credit decisions and help formulate more precise and effective credit strategies. Therefore, the model must possess efficient predictive capabilities and provide transparent and easily understandable result interpretations.
In summary, this study aims to improve the accuracy, reliability, and interpretability of credit card approval process through the application of big data and data mining knowledge. By deeply analyzing application data and constructing efficient predictive models, we help financial institutions better identify potential customers and optimize credit resource allocation. In this context, the Random Forest model excels in handling complex data structures and uncovering feature importance. As a supervised learning algorithm, the Random Forest model provides an effective solution for predicting credit card applicant classifications.
II. Research Problem
- How to design and implement efficient data mining steps to adapt to a dynamic economic environment and maintain high reusability?
- How to interpret duplicate, anomalous, and missing data? Do these values have potential effects, and how to handle them to optimize the model?
- Which key features play a decisive role in the classification of credit card applicants?
- How to evaluate the credit card applicant classification prediction model?
III. Research Objectives
Develop a Predictive Model:
- Create an efficient model to classify credit card applicants using historical credit payment data and application information.
- Ensure the model performs well with new data and accurately predicts credit risk.
Optimize Data Processing Steps:
- Design and implement adaptable data mining steps to handle an evolving economic environment.
- Address duplicates, anomalies, and missing data using EDA and appropriate optimization methods.
Identify Key Features:
- Analyze key features that affect credit card applicant classification.
Evaluate and Optimize Model:
- Use advance metrics to measure and enhance performance.
- Continuously monitor and improve the model's robustness and reliability.
IV. Literature Review
The academic community has long been interested in the application of data mining techniques, particularly machine learning methods, in the field of credit card approval process. The following are discussions and summary of the application of several machinelearning techniques in this field.
Decision trees and logistic regression play an important role in building predictive models. Subashini and Chitra (2013) enhanced fraud detection accuracy in the credit card approval process using classification models based on decision trees (C5.0 and CART), Support Vector Machines (SVM), and BayesNet. [3]
Awoyemi et al. (2017) compared several data mining techniques, including Naive Bayes, knearest neighbors, and logistic regression, for detecting credit card fraud. Their research emphasized the importance of selecting the appropriate algorithms to optimize the credit approval process.[4]
Subasi and Cankurt (2019) used the Synthetic Minority Over-sampling Technique (SMOTE) to handle imbalanced datasets. Their study found that random forests achieved the highest accuracy in predicting default payments, significantly improving performance metrics. [5]
Hsieh and Hung (2009) introduced an ensemble classifier combining neural networks, Support Vector Machines, and Bayesian networks. [6]
These studies demonstrate the diversity and effectiveness of machine learning algorithms in optimizing the credit card approval process. From neural networks and logistic regression to ensemble classifiers and hybrid models, they provide a solid base for future research and applications.
V. Research Methodology
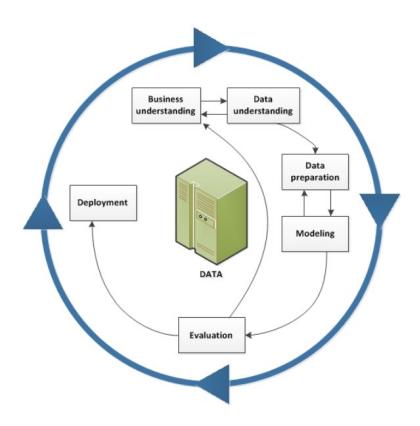
Figure1 – CRISP-DM Methodology
This research is conducted based on the Cross-Industry Standard Process for Data Mining (CRISP-DM) methodology [7] and includes the following steps:
1. Business Understanding
At the beginning of the study, the business objectives were clarified: classify credit card applicants to optimize the credit card approval process, enhance profitability, and improve customer satisfaction. By scoring and classifying applicants, financial institutions can better manage risk, ensure effective resource allocation, reduce potential default risks, and enhance overall operational efficiency and customer satisfaction.
2. Data Understanding
In the data understanding phase, open-source credit card application and credit record datasets were obtained from the internet, and exploratory data analysis (EDA) was conducted to understand the data's structure, attributes, and quality. Data visualization techniques such as histograms and bar charts were used to further comprehend the data distribution and potential patterns. These analyses helped identify anomalies and trends in the data, providing guidance for subsequent data preparation.
3. Data Preparation
Data preparation included handling missing values, data construction, data merging, and data formatting. As a crucial step in the entire data mining process, systematic and meticulous data preparation was carried out to ensure high data quality and efficiency, providing a solid foundation for subsequent modeling and analysis.
4. Modeling
For the processed dataset, the Random Forest machine learning algorithm was applied, model parameters were set, and the model's performance and outputs were recorded. This ensured the model could run successfully and generate predictive results.
5. Evaluation
The model's performance was evaluated using key performance metrics such as accuracy, precision, recall, and F1 score, ensuring effective classification of credit card applicants and identification of important patterns in the data. By analyzing the model's outputs, it was possible to understand which features were most important in the decision-making process. Visualization tools were employed to display the model's performance and feature importance, aiding in understanding and interpreting the model's decisions.
6. Iteration
During the iteration process, data processing steps were adjusted, the modeling was re-run, and the model was re-evaluated. This iterative process helped eliminate biases caused by improper data handling and optimized the data mining process.
7. Deployment
Finally, in the deployment phase, the bestperforming data mining process was applied to the practical handling of credit card applications. This step involved integrating the model into the financial institution's decisionmaking framework to streamline the credit card approval process.
VI. Process Design
The following process outlines the process by which I convert the original credit data into valuable insights:
Data Collection: Credit data was obtained from open-source datasets, including applicants' personal information, financial status, employment history, and credit records. This diverse and rich data provided a solid foundation for the analysis.
Data Cleaning and Preprocessing: Data cleaning and preprocessing are critical steps to ensure data quality and consistency. Missing values were handled using imputation or deletion methods. Outliers were detected and duplicate records were removed to avoid data redundancy. New variables were constructed to simplify the dataset and reduce the complexity of data preprocessing. Multiple data sources were merged into a comprehensive dataset. Finally, all fields were assigned the correct data types, enabling accurate parameter processing and improving the algorithm's efficiency.
Data Transformation: Data transformation involved feature engineering to create a meaningful set of features to enhance the model's predictive power. This included horizontally and vertically trimming the dataset, removing irrelevant columns and rows to streamline the data. Logarithmic transformations were applied to skewed data (such as income) to ensure uniform data distribution.
Selection of Data Mining Methods: Based on the project's objectives, the most suitable data mining method was selected. Classification analysis was chosen for this study as it directly addresses the problem of classifying credit card applicants.
Selection of Data Mining Algorithms: After evaluating multiple algorithms, the Random Forest algorithm was chosen. The Random Forest algorithm is highly accurate and robust, capable of handling high-dimensional data and providing reliable predictions. It also evaluates the importance of features, offering insights into the significance of each feature in the decision-making process. Its flexibility and scalability make it easy to implement and suitable for large-scale data processing.
Data Splitting: The dataset was divided into training and testing sets to ensure the model had enough data for training and validation. This balance helps build a robust model with good generalization capabilities for new data.
Model Training: The Random Forest model was trained on the training set and evaluated on the testing set. Relevant model parameters included the target variable (labelCol), the set of features (featuresCol), the number of trees in the forest (numTrees), and the random seed (seed) to ensure accuracy and reproducibility of the results.
Outcome Visualization: Visualization tools were used to present the model's performance and feature importance. Performance metrics displayed included accuracy, precision, recall, and F1 score. Feature importance charts highlighted the most influential features in the model's decision-making process. ROC graph showed the performance of the model, while confusion matrices also illustrated the model's classification results, including true positives, false positives, true negatives, and false negatives, helping to understand the model's performance across different categories.
VII. Implementation
In this study, I utilized various algorithms and technical tools for different iterations. The tools used include IBM SPSS Modeler as well as open-source Python tools such as Spyder and Jupyter Notebook. Below are some key implementation steps detailed.
Exploratory Data Analysis (EDA) and Data Visualization: During the EDA phase, two powerful Python libraries, Pandas and Matplotlib, were employed. Pandas was used for data processing and manipulation, allowing efficient handling and analysis of large datasets. Matplotlib facilitated data visualization, helping generate various types of charts, such as scatter plots, bar charts, and box plots. These visualizations enabled the observation of data distributions and relationships, thereby uncovering potential issues and patterns.
Outlier Detection: Detecting and handling outliers is a crucial step in data processing. The Interquartile Range (IQR) algorithm [8] was used to identify outliers.
Data Merging: To construct a comprehensive dataset, multiple data sources were merged into a single complete dataset. During the data merging process, inner join operations were used to ensure that only matching ID rows from all data sources were retained. This method guaranteed data integrity and ensured the accuracy and consistency of each data point, providing a reliable foundation for subsequent analysis.
Handling Skewed Data: For skewed data (such as total income), logarithmic transformation methods available in the Numpy library were used for normalization. Logarithmic transformation effectively reduced skewness, making the data distribution closer to normal.
Utilizing Computing Resources: To address the computational demands of large-scale data and complex models, remote high-performance computing resources, specifically AWS instance servers, were utilized. The highperformance computing resources provided by AWS significantly accelerated the model training and inference process, allowing large datasets to be handled and complex models to be trained in a shorter time. This use of remote computing resources not only improved efficiency but also enabled the processing of larger datasets and more complex models.
VIII. Findings and Interpretation
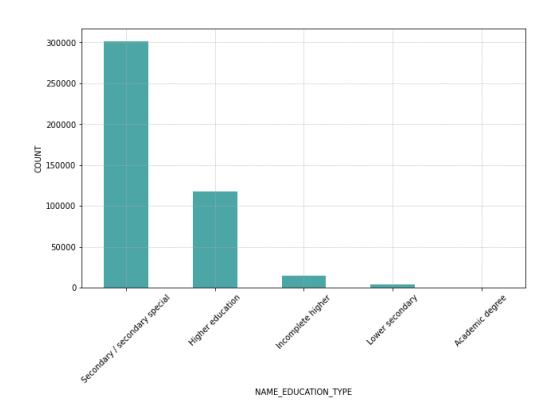
Figure 2 - Count of credit applications for each education type
Figure 2 displays the number of data points for each of the 5 types of education in the researched dataset. The education type "Secondary/secondary special" has the most data points, while "Academic Degree" has the fewest.
| precision | recall | fl-score | support | ||
|---|---|---|---|---|---|
| 01 | 0.560.91 | 0.340.96 | 0.420.93 | 13118622 | |
| accuracymacro avgweighted avg | 0.730.86 | 0.650.88 | 0.880.680.86 | 993399339933 |
Figure3 – Classification Report
The performance of the Random Forest classifier using the Sklearn library on both the training and testing sets is shown in Figure 3. The overall accuracy is relatively high. The model performs particularly well in predicting "good client" (Category 1). Specifically, the precision is 0.91, meaning that 91% of the predictions for low-risk clients are correct.
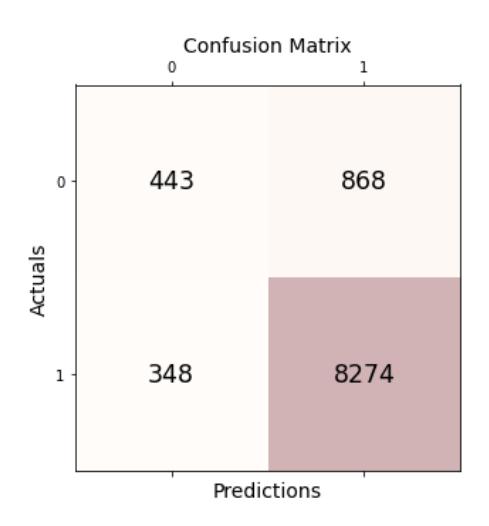
Figure 4 - Confusion Matrix
The confusion matrix in Figure 4 shows that the majority of clients are low-risk, suggesting that the dataset may be imbalanced.
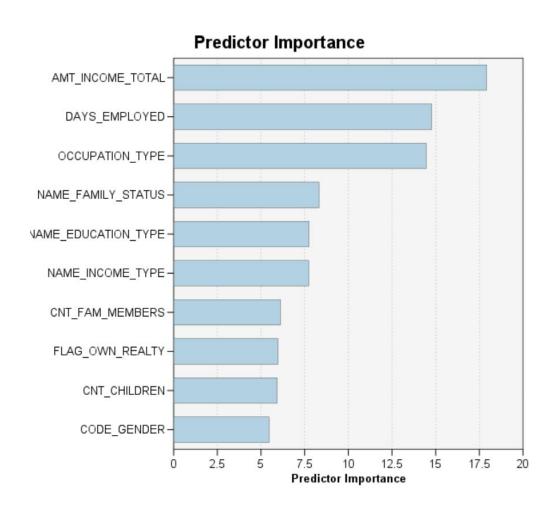
Figure 5 - Feature Importance
Feature importance analysis using SPSS Modeler shows that DAYS_BIRTH is the most influential feature, suggesting that older applicants are more likely to be classified as low-risk clients. DAYS_EMPLOYED is another critical factor, where longer employment duration usually indicates higher financial stability and reliability. Finally, OCCUPATION_TYPE is also identified as an important predictor variable.
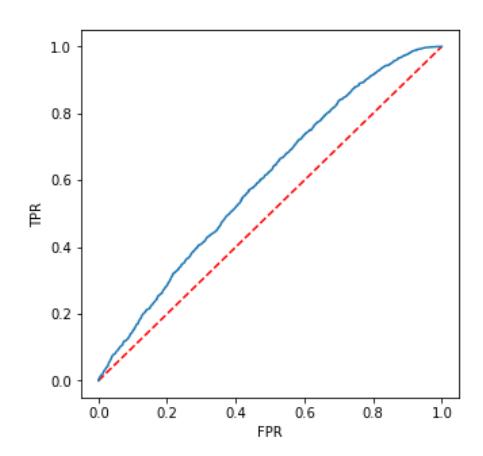
Figure 6 - Receiver Operating Characteristic Curve
ROC curve analysis using the Random Forest classifier from the PySpark library provides an overview of the model's overall performance. Although the current graph shows mediocre performance, further optimization and adjustments could enhance the model's performance.
IX. Limitation
A significant challenge in current data mining modeling is imbalance. Specifically, the model performs well in predicting the majority class (low-risk clients) but poorly in predicting the minority class (bad payers). This issue may arise due to the overrepresentation of the majority class in the training data, causing the model to favor majority class predictions. To address this problem, techniques such as Synthetic Minority Over-sampling Technique (SMOTE) can be used. Additionally, while the model has identified age, employment stability, and income as key features, there may be other variables not included in the model that also affect credit scores. Therefore, further feature engineering and the inclusion of more relevant variables are necessary to improve model performance.
Although the model performs well on the test set, we need to verify its robustness across different datasets. By conducting crossvalidation and testing on independent datasets, we can more comprehensively evaluate the model's performance.
Improving the model should be an ongoing process. We need to update the model with new data based on performance feedback and explore alternative algorithms to enhance prediction accuracy and fairness. Specific improvement strategies include balancing the dataset by oversampling the minority class or undersampling the majority class, introducing more relevant features or transforming existing features to capture subtle patterns in the data, experimenting with different hyperparameters and algorithms to find the optimal configuration, and considering more complex methods such as ensemble learning or gradient boosting to increase model accuracy.
X. Proposed Actions
Based on prevoius research findings, we propose the following knowledge-driven recommendations to optimize the credit card approval process:
Targeting Specific Age Groups: The results of the analysis show that older age groups exhibit more favorable credit behavior. Therefore, it is advisable to focus on issuing credit cards to these age groups, while being more cautious in approving younger groups. This targeted approach helps to reduce the risk associated with these populations.
Prioritize Long-Term Employee: Employment stability is a strong indicator of financial reliability. Hence, it is recommended to prioritize credit card approvals for individuals who have longer employment tenures. This criterion can serve as a proxy for income stability and reduce the likelihood of defaults.
Leverage Data-Driven Decision Making: Encouraging banks to integrate advanced data analytics into their credit card approval processes can significantly improve decision accuracy. By increasing the proportion of machine-driven decisions and reducing the reliance on manual assesments, banks can achieve more consistent, unbiased, and efficient outcomes. This shift towards data-driven decision making can harness the predictive power of machine learning models, leading to better risk management and customer satisfaction.
Enhance Credit Card Application Forms: To capture a more comprehensive profile of applicants, it is crucial to optimize the credit card application forms. These froms should be designed to gather detailed information across various parameters. By doing so, banks can obtain a more holistic view of an applicant's creditworthiness, enabling more informed and accurate decision making.
Adopt Continuous Monitoring and Feedback Loops: Implementing continuous monitoring sytems to track the performance of approved credit card holders can provide valuable feedback for refining approval criteria. By analysing patterns and outcomes, banks can adjust their models and strategies dynamically, ensuring that the approval process remains responsive to changing market conditions and customer behaviours.
Improve Financial Literacy and Customer Education: Enhancing the financial literacy of potential and existing customers can lead to more responsible credit card usage. Banks should invest in educational programs and resources that help customers understand credit management, budgeting, and the importance of maintaining a good credit score. Educated customers are more likely to use credit cards wisely, reducing default rates and improving overall portfolio performance.
By implementing these knowledge-driven actions, banks can optimize their credit card approval processes, reduce risk, and enhance customer satisfaction. These strategies not only improve the efficiency and effectiveness of credit card issuance but also contribute to the long-term stability and profitability of the banking institution.
XI. References
[1] Martin, E. J. (2023, December 22). Credit card ownership and usage statistics. Bankrate. https://www.bankrate.com/finance/credit-cards/credit-card-ownership-usagestatistics/#stats
[2] Johnson, H. (2024, January 8). History of Credit Cards: A Brief Overview · TIME Stamped. TIME Stamped. https://time.com/personal-finance/article/history-of-credit-cards/
[3] Subashini, B., & Chitra, K. (2013). Enhanced System for Revealing Fraudulence in Credit Card Approval. International journal of engineering research and technology.
[4] Awoyemi, J., Adetunmbi, A., & Oluwadare, S. (2017). Credit card fraud detection using machine learning techniques: A comparative analysis. 2017 International Conference on Computing Networking and Informatics (ICCNI). https://doi.org/10.1109/ICCNI.2017.8123782.
[5] Subasi, A., & Cankurt, S. (2019). Prediction of default payment of credit card clients using Data Mining Techniques. 2019 International Engineering Conference (IEC). https://doi.org/10.1109/IEC47844.2019.89505 97.
[6] Hsieh, N., & Hung, L. (2009). A data driven ensemble classifier for credit scoring analysis. https://doi.org/10.1016/j.eswa.2009.05.059
[7] IBM. (2021, August 17). CRISP-DM Help Overview. Www.ibm.com.https://www.ibm.com/docs/en/spssmodeler/SaaS?topic=dm-crisp-help-overview
[8] Wikipedia Contributors. (2019, November 21). Interquartile range. Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/Interquartile_ran ge
